Following the announcement of our code review pilot, we heard about a group in the social and ecological sciences who were also exploring methods of code review in their discipline through a project called “COMSES Net”.
The issues we hope to address through our pilot with PLOS Computational Biology are not life science specific. Ecologists, earth scientists, social scientists and more are grappling with many of the same problems, as their work, too, becomes more computationally dependent and driven.
Part of our work at the Science Lab is in helping to increase awareness of initiatives around the world pushing the boundaries of sharing scientific knowledge, tools for better research, and means to get involved. It’s with that that I’m delighted to welcome Michael Barton to the blog to tell us more about the COMSES Network, OpenABM and their approach to code review for the social sciences.
Kay Thaney: Michael, thanks for joining us. To start, could you tell us a bit more about the project – where the idea came from, what you hope to achieve, how long you’ve been up and running?
Michael Barton: CoMSES Net (or the Network for Computational Modeling in the Social and Ecological Sciences) is a “Research Coordination Network” funded by the National Science Foundation. It originated in an NSF proposal review panel in 2004 on which one of the project’s co-Directors (Lilian Alessa) and I served, which made clear the growing importance of computational modeling to the future of socio-ecological sciences.
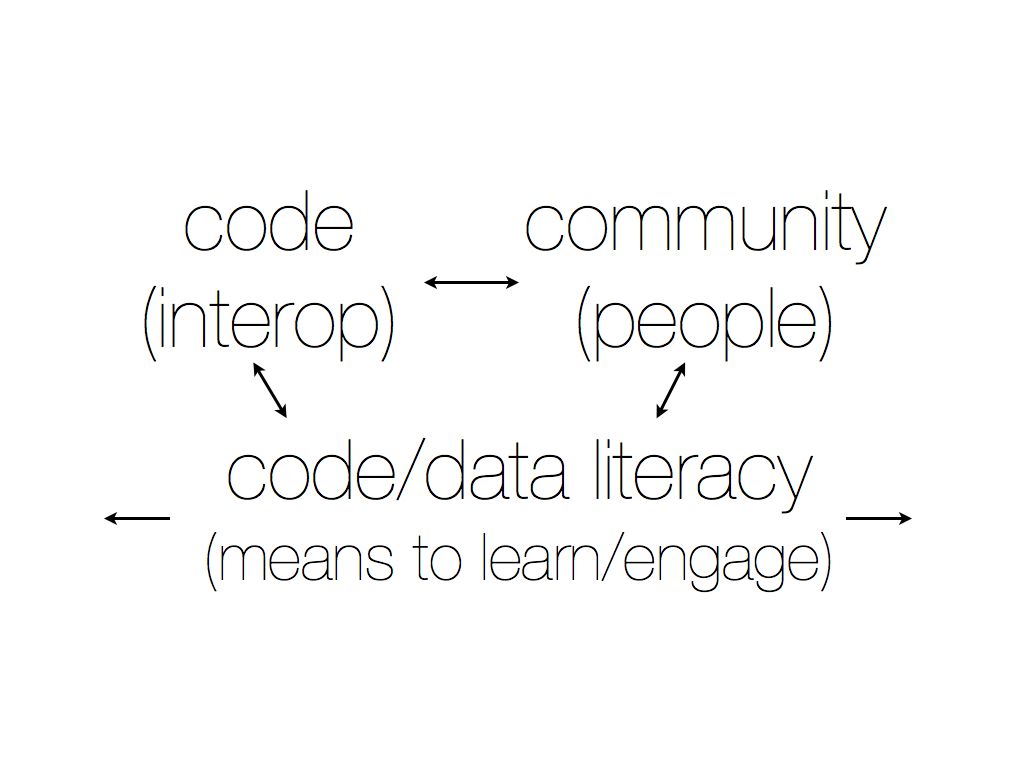
With NSF support, we convened a series of workshops and initiated a pilot project to better understand the challenges to making model-based research a part of normal science in these fields. Importantly, we learned that a key issue was the lack of ways for researchers to share knowledge and build on each others’ work–a hallmark of scientific practice. This led to the formation of the Open Agent Based Modeling Consortium (OpenABM), whose main aim was to develop a roadmap for improving the exchange of scientific knowledge about computational modeling. This pilot program had a number of useful outcomes–including improved interoperability between different modeling platforms, support for emerging metadata standards, a community web site, and recommendations for ways to share model code and educational materials. It also led to a subsequent NSF grant that created CoMSES Net in 2009.
CoMSES Net has been active for four years. In that time, we’ve implemented many of the recommendations of the pilot program, and gone beyond those recommendations in some areas. We’ve had a workshop on best practices for code sharing and promoting quality code, and another on modeling in education.
Particularly relevant for the code review that the Mozilla Foundation is exploring, we created the Computational Model Library (CML), where authors can publish scientific code and have negotiated an agreement with the Arizona State University Libraries to provide “handles” (open source DOI equivalents from the same organization that provides DOI’s) to peer reviewed models. We have established agreements with journals that publish model-based science to require or recommend that authors publish code with the CML, and created a protocol to enable code review simultaneously with the review of a submitted manuscript. We have also established an internal code “certification” program for peer review of code not associated with journal articles.
Kay Thaney: COMSES focuses on ecological and social science research. For those readers unfamiliar with those disciplines, what are some examples of code and software use in that sort of work? Is this a recent development, using more computational modeling and digital analysis in the discipline?
Michael Barton: Modeling and computation is becoming pervasive across many fields of science, engineering, and technology. Our focus is on the social and ecological sciences. These domains are increasingly ‘fuzzy’ around the edges, as human activities are affecting biophysical earth systems in more and more profound ways, and as we become increasingly concerned about the social dimensions of science, engineering, and technology. As a community, we are working to better delineate the scope of CoMSES Net in this changing social and intellectual environment. Still, at the core, this encompasses social organizations and institutions that emerge from the interactions of decision-making human actors who share cumulative cultural knowledge to varying degrees, and their evolution over time. It equally encompasses the evolution, behavior, and interactions of other living organisms–with each other, with the human world, and with the earth’s physical systems.
There is a long history of statistical analyses in the social and ecological sciences, the application of equation-based models in a few fields (e.g., economics and behavioral ecology), and some limited experimentation with computer simulations. But spread of computational modeling–especially models that take a bottom up approach representing many, discrete, decision-making agent–is a comparatively recent phenomenon of the past decade. Often these also employ complex systems conceptual approaches to explore how simple rules expressed by multiple interacting agents can lead to the emergence of complex phenomena at more inclusive scales. Examples include models of farmers managing a shared irrigation system, foraging behavior of ants, and flocking in birds.
Kay Thaney: You had mentioned in a comment to our initial post on our pilot that your team were endeavoring to work on new forms of review for code and software. Tell us more about your approach.
Michael Barton: Our approach to software and code review is to embed it into forms of scientific practice and reward systems that are familiar to most practitioners. We have created two pathways for code review. In one pathway, scientists who publish a journal paper that involves computational modeling can submit their code to the CML but leave it unpublished. They then can provide the URL of the code to a journal editor and/or reviewers for evaluation along with a submitted manuscript. Editors and reviewers can access the code, but it remains hidden from others. Authors can revise the unpublished code in response to reviewer comments, in the same way as they can revise a submitted manuscript. When the paper is published, author can then click a button to publish the code in the CoMSES Net library, making it accessible to the scientific community.
The second pathway is for code that is not directly associated with a journal publication. An author can request peer review and “certification” for a model submitted to the CML that either is published or unpublished. Certification follows a protocol that is similar to manuscript review for a journal, practices familiar to most scientists. A set of peer experts is selected to review the code, following a set of reviewer guidelines. Reviewers can request revision of the code or documentation. When the editor is satisfied that a code author has satisfactorily responded to peer review, the model is “certified”. This adds a certification badge to the model entry in the CML. The CoMSES Net certification review guidelines emphasize model functionality and documentation. The model should be sufficiently documented that another researcher can understand its operation and replicate its functionality. It should also function as described—including running in the environment specified. We are following something of a PLOS model for evaluating scientific value of the code, providing space for commentary and rating by the larger community of practice.
Code that has passed peer review via either pathway is assigned a “handle” from the Handle System (http://handle.net), which manages “persistent identifiers for internet resources”, through our agreement with the ASU Libraries. A DOI is a well-known, commercial implementation of Handle System resource identifiers. The CML provides a formatted citation for all published models, making them potentially citable in other papers and on professional CVs or resumes. A handle in a model citation, as a permanent resource identifier, is an added indicator of quality for code that has undergone peer review. Moreover, all individuals who join CoMSES Net as affiliate or full members (required for publishing code) must agree to a set of ethical practices that include proper citation of model authors.
Kay Thaney: What have you found this far in your efforts? Any interesting outliers or behaviors?
Michael Barton: All scientists who engage in model-based research that we have talked with have been strongly in favor or our efforts. However, this community has been slow to publish models. This is not unexpected, of course, as it is a change in established practice. We hope that as the CML grows and becomes an increasingly valuable resource, scientists’ reputations will be enhanced by publishing code, as they are by publishing manuscripts. If this happens, it can initiate a positive feedback loop of increasing code publication and enhanced reputation for publishing code. That is what we’d like to see ultimately.
Kay Thaney: How much of a technological problem do you think this is? What would you identify as some of the blocking points in your discipline that are keeping these practices from becoming the norm?
Michael Barton: I mentioned above, we were initially surprised to learn that the spread of computation in the social and ecological sciences has a more important social dimension than technological dimension. There are certainly technological aspects. But peer review and evaluation of scientific code is a social process that requires voluntary participation by reviewers and those who submit their code for review. All participants need perceive potential benefits. We are working to establish a community-recognized system of mutual benefits that will encourage scientists to share their knowledge and improve scientific computation. While enforcement by traditional publishing venues and granting agencies will be important, is system of rewards is perhaps even more important.
The technological issues involved is providing the environment where all this can happen–including a place where code can be accessed by the scientific community and where peer review can take place. The CoMSES Net community is working to provide such an environment. We hope it can serve as an exemplar for other scientific communities of practice who recognize the importance of scientific computation.
Finally, it is increasingly important to provide new opportunities for training in computational thinking across all scientific domains. This is not computer science per se, but the ability for scientists to express dynamic systems in algorithmic terms—and sufficient knowledge of computing platforms to instantiate these algorithmic expressions in environments where they can help to solve wicked problems.
Kay Thaney: Fascinating – and very in line with our initiatives. Anything else about COMSES Net to mention?
Michael Barton: CoMSES Net has also created discussion forums, including a very active jobs forum for expertise in computational modeling. The web portal is developing as a locale for sharing educational materials, training materials for modeling, links to modeling software sites, and we recently started a YouTube channel for educational videos on computational modeling.
In addition to providing a community and framework for knowledge exchange, we hope to establish protocols that help scientists to receive professional recognition for creating and publishing scientific code, in ways that parallel recognition for carrying out and publishing other forms of research. The rapidly growing importance of computation across all domains of science make it imperative that it be embedded in the kind of knowledge scaffolding that has been a key driver behind the scientific transformation in the way we understand our world.
Kay Thaney: Thank you again for joining us and sharing information about your work.