It’s been just over two months since we announced the start of the Mozilla Science Lab, and I wanted to share with you our thoughts on how to structure our activities moving forward.
Our aim from the beginning has been to see how we could best support and extent the existing work going on in “open science” – in some cases bridging existing technologies to address new problems, in others providing the educational resource to help close the gap in skills and awareness. And on top of that, map some of the core values and areas of expertise of Mozilla to science (e.g., openness, digital literacy, open-source ethos, community), like we did at Creative Commons years ago with the science project.
To ensure sure we were not just operating off of assumption regarding what the community needed (especially one as diverse, dynamic, and with as many stakeholders), we hit the road (literally and somewhat figuratively speaking, thank you Skype). Over the course of the last 2+ months, I’ve spoken to rooms of 20 / 300 / 700 asking for their feedback, and had a series of 1-on-1 calls and meetings with researchers from a diverse sample of disciplines (earth science, biology, ecology, social science, astronomy, physics), policymakers, publishers, tool developers, and educators.
What we learned
- There’s a *ton* of activity (tool development, community efforts, policy work) pushing things forward, but we’re not nearly there yet.
- It’s difficult to know what all is out there – what software exists, who’s tried what (and with what successes), how others can get involved. This is keeping many projects from gaining the traction they need. We need a better means of communication (about and among efforts) so we can reduce duplication, foster collaboration and gain broader use. (GiveWell’s recent post on the current open research landscape is a great start, but there’s still more we can do.)
- The system is complex and reliant upon a diverse network of stakeholders and technologies. The vernacular, behavior and idea of what “making the web work for science” among these groups also varies greatly, and needs to be taken into consideration as we craft solutions.
- We’re facing an ever-widening skills gap. Science is becoming increasingly computationally-dependent, web-enabled and data-driven, yet our training is still based around older methods of doing research rooted in the analog. For there to be a real sea change in the behavior of researchers … for us to make research more open, collaborative and reproducible, we need better training and education tailored towards these aims.
How we can help
It was clear that there is a pressing need for coordination, interoperability, and better communication in this space, whether you’re building digital infrastructure for high performance computing, building open source tools for visualisation, or looking for new (open) means of doing your research in the lab. Taking everything we heard into consideration, we distilled that activity down into three core areas, each mutually dependent upon one another. We view each of these areas as key to filling in some of the gaps in this space, as well as providing the infrastructure and support for the breadth of activities already going on.
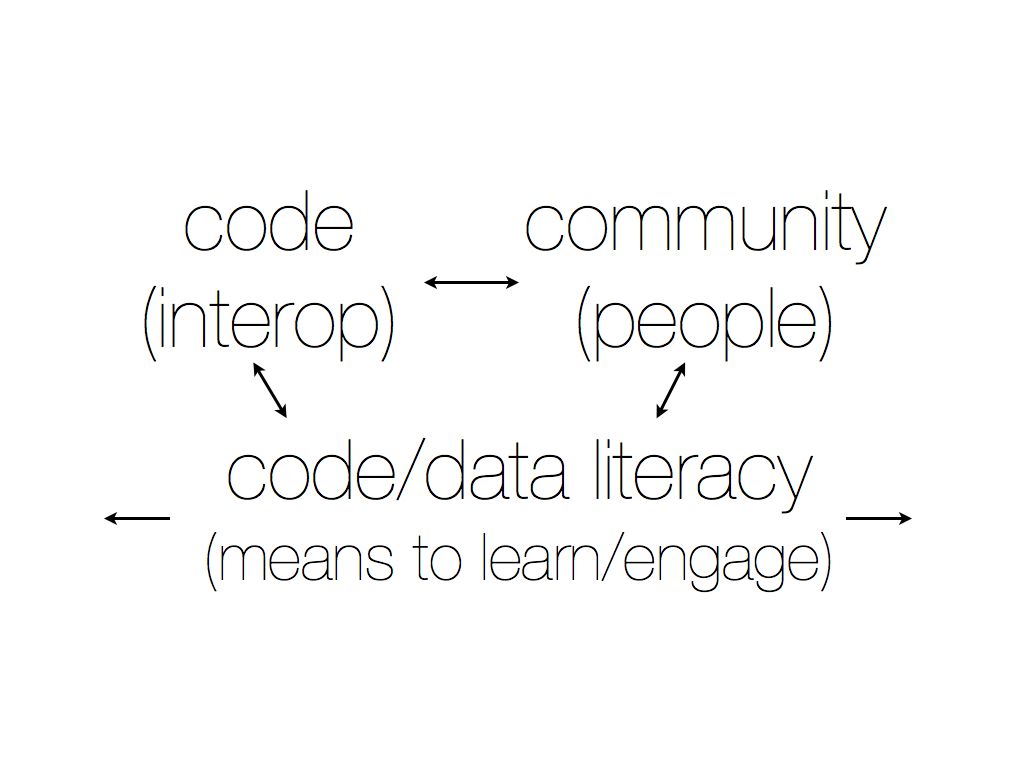
Let me go into a bit more detail about each of these areas, to help you better understand our programmatic focus moving forward. We’ll be elaborating on each of these areas in a series of subsequent posts, as well.
Code
Through this work, we’ll be engaging with other external groups (scientific startups, publishers, researchers, etc.) to help bridge existing technologies where possible, build our prototypes to explore new problem sets, and supporting existing development in the community. An example of this could be taking an existing tool that may be discipline-specific and working to see if it can be applied to a different field. Or it could be taking existing infrastructure (say, the badges work) and working with external groups to test out different implementations.
Our aim here will be to serve as a means to bring together community around best practice, and also support existing work and extend it through small prototyping bursts of activity, collaborations and internal development.
We currently have one pilot running with the help of PLOS Computational Biology, exploring what code review for science could look like. See our recent post on this for more information.
Code and Data Literacy
Running in parallel to all of our other efforts in building community, communities of practice and open tools is a skills training layer, exploring what “digital literacy” for science means. Research is becoming increasingly digital in nature – data-driven and in many cases computationally-dependent – yet digital skills such as version control, visualization, analysis and online collaboration are not often taught at the university level. There’s an increasing gap between what researchers are expected to know, and what they have access to training wise. And practices fundamental to doing open, reproducible science are still outside of most formal training at the university level, despite increased availability of free, open tools for data sharing, collaboration, electronic lab notebooks and external pressures from funders.
Our work will help bridge that gap – in part by making such training accessible and attainable to all, so that scientists can do better, more digitally-enabled research.
Software Carpentry is our main activity in this space to date, a project founded by Greg Wilson to help teach basic computing skills to researchers. This is done via short two-day bootcamps, taught by a volunteer instructor base all around the world. We hope in the future to be able to build out additional components and work with others in the community exploring different approaches to heightening digital literacy for research.
Community
Last but not least is our focus on building and supporting community around the work mentioned above. We hope to be that connective tissue between various bursts of activity, understanding and practice, providing a focal point for information on developments in this space and a means for others to plug in. Mozilla has a longstanding history in building community, and we want to use that know-how to amplify the work currently going on, build communities of practice around openness, and serve as the glue to bring interested parties together. Engagement is also high on our priority list, exploring how best to use the expertise and enthusiasm of the community to help push these ideas forward.
We will be announcing later this year an international effort that hopes to do just that – so do stay tuned. 🙂
And in the shorter term, we’ll soon be announcing our first community call which will give you a chance to interact directly with us and help us continue to shape the Science Lab, hear about new tools and projects in this space, and learn more about what we’ve got cooking for 2014.
To wrap up
We view these three areas as the support beams for the open research community. You’ll notice arrows showing flow between each of those core areas, as well – that’s intentional. From a technical partnership starting a broader conversation with the community about best practice to a gap raised in our training efforts turning into a technical project, we view these areas as interdependent and mutually reliant upon one another. Moving forward, our hope is to also use model as a means to assess new opportunities, build out new programs and measure our successes.
I’ll be going into more detail about our activity in these three areas over the coming weeks. In the meantime, we’d love to hear your thoughts. Feel free to chime in here in the comments, send to mail or find me on IRC @ kaythaney.

You mentioned irc. Does mozilla have a particular irc channel related to this?
Just created one (#sciencelab), but not heavily used at present. 🙂
I would like to express my concern over the lack of entry-level information about open science and to propose one part of the solution to addressing this problem.
It is my opinion that if a person who does not understand concepts like open science, open access, what Lessig called “free culture”, Creative Commons licenses, or other concepts which must be understood as a prerequisite to caring about the movement, then people who want to learn more and become involved will remain unable to become involved.
I cannot plan how to educate everyone, but I would like to see those people who want to educate themselves to be well-served. Right now, to get a quick overview of anything, people often type terms into their favorite search engine and read a bit of what comes up. I would encourage anyone who wants to do outreach to imagine their audience doing just that – type “open access”, “open science”, “free culture”, “Creative Commmons”, and other like terms into a search engine. What does one see? I see Wikipedia, and anyone can contribute good content to Wikipedia.
When a Wikipedia exists to cover a given topic, then that article becomes search engines’ recommended source of information. Anyone whose audience is includes search engine users is a stakeholder in Wikipedia articles which are returned by searches interesting to them. I contribute to Wikipedia articles. Wikipedia is also a great way to communicate with and support the layman community interested in giving moral support to science projects and advocacy efforts. If any other open science people would like to join me then contact me and I will show you how. I also need non-text illustrative media for articles if anyone has ideas about how to depict the movement. Thanks.
Thanks for your comment. I completely agree with you – and part of what our community efforts will involve will be creating better entry-level resource for those looking to learn more about open science and its applications/implications, as well as a means for others to better access and engage with work going on in this area already. Part of that will be through our blog and website (under construction as we speak), our soon-to-start community calls, but we’re also thinking beyond that so that there are clear, digestible resources for others to use. Our goal is to create a focal point for this resource, eliminate a bit of the mystery and lower the amount of chase involved to learn more. 🙂
Would love to hear your thoughts on what would be of most use to you. Feel free to ping us at [email protected] or find me on IRC (kaythaney – also lurk in the #sciencelab IRC channel).
Thanks again!
Hey,
I think you are absolutely right about different groups not talking much to one-another. Evrybody seems to be concerned about their own project or area of science and not caring too much about others.
One of the things we found especially difficult when making Fidus writer, was that the parts of the browsers that permit editing. All the browsers have several bugs in this area which one can only get around by writing large amounts of extra (javascript) code. It means that it’s really difficult to start new projects that involve writing/editing texts. I tried to report the issues and get on the email list for Webkit/Firefox/Chrome about it. The Chrome people gave some feedback, but so far I haven’t heard much back from the Firefox community ( https://bugzilla.mozilla.org/show_bug.cgi?id=873883 ).
Text production is quite fundamental within most sciences. So I was wondering: Do you guys also work with connecting the Mozilla Firefox people with roups creating web tools for the sciences?
At any rate, the Science Lab is a great project! Congratulations!